
Wer kennt es nicht? Abfragen an Datenquellen über die ganze Anwendung verteilt. Dort mal eine Abfrage, dort mal eine Abfrage und häufig deckt sich der dabei verwendete Code auch noch. Manchmal mit kleinen Abweichungen, aber ob dies ein Bug ist, kann schon lange niemand mehr beantworten. Dann auch noch Änderungen an einer der angebundenen Datenquellen und schon wird der Sourcecode durchforstet, in der Hoffnung, alle darauf aufbauenden Stellen zu finden.
Ein alltägliches Szenario, das es so nicht geben müsste. Aber in zahlreichen Anwendungen findet sich immer wieder dasselbe Bild:
- Zugriffe auf dieselben Datenquellen an unterschiedlichsten Stellen
- Doppelter Code an allen Ecken und Enden
- Workarounds um zumindest an einigen Stellen etwas ähnliches wie Caching anzubieten
- Kaum Tests (da man ohnehin nicht weiß wo man mit dem Testen beginnen sollte und wie man daraus einen sinnvollen Unit Test gestaltet)
Angesprochen darauf erhält man vielfach die Rückmeldung, dass es sich doch um ein gewachsenes System handelt. Das alles erschlagende Argument. Und das bei Projekten, die teilweise noch kein Jahr am Rücken haben. Das muss so nicht sein!
Repository Pattern
Salopp gesagt entspricht das Repository Pattern der Auftrennung zwischen Businesslogik und der Datenbeschaffung, unabhängig der Datenquelle. Wie bereits oben beschrieben wird häufig in der Businesslogik auf Datenquellen zugegriffen, um diverse Daten zu laden, diese in Objekte zu mappen und um diese anschließend anzuzeigen und/oder zu manipulieren. Nun stelle man sich eine größere Anwendung vor. Quer durch sämtliche Businesslogik wird nun auf Daten zugegriffen um diese zu manipulieren. Jedes Mal derselbe Code.
Ein Repository bringt eine zentrale Zuständigkeit ins Spiel. Nämlich eine zentrale Stelle, die sich darum kümmert, den Zugriff zu Entität XY zu gewähren (woher auch immer) und eine Anlage/Änderung in einem korrekten Zustand weiter zu leiten. Die Businesslogik selbst verwendet das jeweilige Repository um auf die Daten zuzugreifen mit dem Vorteil, dass alle relevanten Stellen denselben Code durchlaufen. Dieser muss dementsprechend nur an einer einzigen Stelle gewartet werden. Selbst Änderungen an der Datenbeschaffung selbst bleibt der Businesslogik verborgen, da nur für das Repository relevant.
Hinweis: Man stelle sich vor, dass bestimmte Daten nun nicht mehr direkt aus einer Datenbank, sondern von einem Service bezogen werden. Bei direkter Einbindung in die Businesslogik müssen zahlreiche Stellen nachgezogen werden. Dies ist mühsam und birgt natürlich immer wieder eine gewisse Fehleranfälligkeit in sich. Eine Pflege an zentraler Stelle ist hier definitiv vorzuziehen.
Grafisch könnte man die Interaktionen so darstellen:

Dabei ist anzumerken, dass das Repository selbst eigentlich nicht für die Datenbeschaffung zuständig ist, sondern lediglich einen Zugriff darauf zur Verfügung stellt. Dafür sprechen mehrere Gründe:
- Die durch ein Repository zu ladende Daten können aus mehreren unterschiedlichen Datenquellen stammen.
- Das Repository bietet “Hilfsmethoden” an, die durch die Datenquelle (beispielsweise ein Service) nicht angeboten wird.
- Kapselung der Datenquelle an eine zentrale – testbare – Stelle und somit einfacher Tausch bei Notwendigkeit.
Beispiel
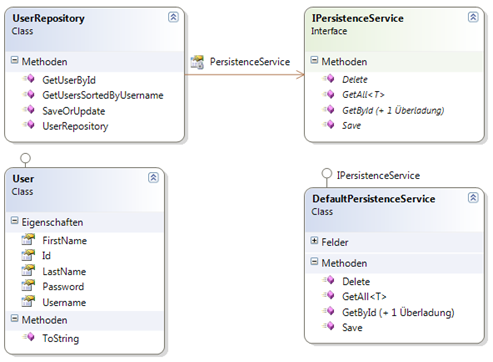
Zur Verdeutlichung sehen wir uns ein kleines Beispiel an. Dieses verwendet folgende Bestandteile:

Dabei stellt die Klasse DefaultPersistenceService die Basis der Datenbeschaffung dar. Das UserRepository stellt Methoden zum Umgang mit Objekten des Typs User zur Verfügung. Dabei bietet die Klasse UserRepository Methoden an, die nicht durch das Service abgedeckt werden. So kann im zu Grunde liegenden Beispiel eine Benutzerliste nach dem Benutzernamen sortiert werden.
public class UserRepository
{
private IPersistenceService PersistenceService { get; set; }
public UserRepository(IPersistenceService persistenceService)
{
PersistenceService = persistenceService;
}
public User GetUserById(long id)
{
return PersistenceService.GetById<User>(id);
}
public IList<User> GetUsersSortedByUsername()
{
List<User> allUsers = PersistenceService.GetAll<User>() as List<User>;
allUsers.Sort(new UserNameComparer());
return allUsers;
}
public void SaveOrUpdate(User user)
{
PersistenceService.Save(user);
}
}
Eine Sortierung der Benutzer nach Benutzername wird durch die Methode GetUsersSortedByUsername angeboten. Dies ist in diesem Beispiel die einzige Methode des Repositories, das zusätzliche Logik mit sich bringt. Grundsätzlich wären hier jedoch weitere Möglichkeiten denkbar.
Repositories testen
Ein zentraler Vorteil der Repositories ist, dass diese ordentlich getestet werden können. In unserem Beispiel hat das UserRepository eine Abhängigkeit zu einem IPersistenceService. In der laufenden Anwendung wird diese Abhängigkeit mittels Autofac gefüllt. Dies ist in unserem Unit Test des Repositories nicht erwünscht. Daher muss die Schnittstelle gemockt werden. Dazu wurde moq in das Beispiel integriert.
Hinweis: Eine reale Implementierung der Schnittstelle
IPersistenceServicewürde mit Sicherheit eine externe Ressource – beispielsweise eine Datenbank – anbinden. Eine Verwendung wäre daher in Integrationstests sinnvoll, jedoch nicht in einem Unit Test.
Ein Blick in die Methode Setup zeigt hier schon, wie ein Mock der Schnittstelle IPersistenceService erstellt wird. Damit das Service auf Anfragen entsprechend reagieren kann, wird definiert, was genau beim Aufruf der Methoden Save, GetById und GetAll geschehen soll. Im letzten Schritt der Test-Initialisierung wird das UserRepository erstellt und kann verwendet werden.
using System.Collections.Generic;
using System.Linq;
using DevTyr.RepositoryPattern.Contracts;
using DevTyr.RepositoryPattern.Models;
using DevTyr.RepositoryPattern.Repositories;
using DevTyr.RepositoryPattern.Services;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Moq;
namespace DevTyr.RepositoryPattern.Test
{
[TestClass]
public class UserRepositoryTests
{
private List<User> persistedUsers = new List<User>();
private UserRepository userRepository;
[TestInitialize]
public void Setup()
{
Mock<IPersistenceService> persistenceMock = new Mock<IPersistenceService>();
persistenceMock.Setup(service => service.Save(It.IsAny<object>())).Callback<object>(
item =>
{
(item as IInstanceIdentifier).Id = persistedUsers.Count() + 1;
persistedUsers.Add(item as User);
}
);
persistenceMock.Setup
(
service => service.GetById<User>(It.IsAny<long>())
)
.Returns<long>
(
item => persistedUsers.Where(user => user.Id == item).FirstOrDefault()
);
persistenceMock.Setup(service => service.GetAll<User>()).Returns(persistedUsers);
userRepository = new UserRepository(persistenceMock.Object);
}
[TestMethod]
public void it_should_be_possible_to_add_a_new_user()
{
long expectedUserId = 1;
var user = new User
{
Username = "firstuser",
FirstName = "Norbert",
LastName = "Eder",
Password = "firstuser"
};
userRepository.SaveOrUpdate(user);
var persistedUser = userRepository.GetUserById(1);
Assert.IsNotNull(persistedUser, "User was not persisted, otherwise it shouldn't be null");
Assert.AreEqual<long>(expectedUserId, persistedUser.Id);
}
[TestMethod]
public void username_eder_should_be_infront_of_maier()
{
int expectedListCount = 2;
string expectedFirstUsername = "eder";
string expectedSecondUnsername = "maier";
var maierUser = new User
{
Username = "maier"
};
var ederUser = new User
{
Username = "eder"
};
userRepository.SaveOrUpdate(maierUser);
userRepository.SaveOrUpdate(ederUser);
var users = userRepository.GetUsersSortedByUsername();
Assert.AreEqual<int>(expectedListCount, users.Count());
Assert.AreEqual<string>(expectedFirstUsername, users[0].Username);
Assert.AreEqual<string>(expectedSecondUnsername, users[1].Username);
}
}
}
Die beispielhaften Tests prüfen nun das Hinzufügen eines neuen Benutzers, als auch die Sortierung der Benutzerliste. Idealerweise mit positivem Ergebnis :)

Dieses Beispiel zeigt zum Einen die Verwendung eines Repositories und wie dessen reine Funktionalität getestet werden kann.
Download Repository Beispiel
Nachfolgend findet sich der Download des Repository Beispiels inklusive der angesprochenen Tests und aller notwendigen Libraries.
Download Beispiel Repository Pattern
Fazit
Bei einer Neuentwicklung ist es sehr ratsam, auf dieses Pattern zu setzen, da vor allem im Zusammenspiel mit Unit Tests eine stabile Schicht geschaffen werden kann. Um jedoch die beschriebenen Nachteile, wie doppelter Code etc. in den Griff zu bekommen, empfiehlt es sich auch, bestehende Implementierungen nachzuziehen. Natürlich ist es schwierig ein bestehendes System derart in der Basis zu verändern, zumal viele Stellen davon betroffen sind. Man sollte sich jedoch vor Augen halten, dass die Qualität wesentlich gesteigert wird und zukünftige Erweiterungen einfacher von der Hand gehen.
Ist ja nicht neu und wird schon mit OR/M und CRUD seit Jahren praktiziert. So sehr, dass völlig in Vergessenheit geraten ist, wie viel mehr als reine Datenspeicher SQL Datenbanken eigentlich sind.
Ich habe das in aktuellem Code mal so “gelöst”. Es wird SQL für Businesslogik genutzt aber der reine objectorientierte Weg alleine schon fürs Verständnis ausformuliert und dann auskommentiert mit einem Hinweis darauf, wie viel schneller und Ressourcenschonender der SQL Weg ist.
Oh, gerade gesehen, dass der Artikel schon recht alt ist, hatte nur auf deine Tweet hin den Artikel heute gelesen :-s
Hallo,
der Artikel ist sehr interessant und nützlich. Allerdings habe ich ein Problem dieses Pattern in meinem aktuellen Projekt umzusetzen.
Ich habe eine Datenbank mit mehreren Tabellen (Artikel, Kategorien, usw.). Für den Zugriff verwende ich das Entity Framework mit Code First-Ansatz.
Die Idee hinter den Repository verstehe ich, mir ist aber unklar wie der PersistenceProvider bei der Verwendung mit meiner Datenbank aussehen muss.
Dessen im Beispiel vorhandene Implementierung macht ja Gebrauch von generischen Typen und legt eine Listen pro Typ an.
Ich gehe davon aus, dass der DefaultPersistenceProvider in der Form nur für den Unit Test verwendet werden würde und eine “real-world” Implementierung welche die Verwendung einer Datenbank kapselt anders aussehen müsste. Nur wie?
Wäre eine akzeptable Lösung hier den Typ über eine Switch-Case abzufragen und eine Exception zu werfen, wenn ein Typ übergeben wird der nicht in der Datenbank vorhanden ist? Es geht doch bestimmt eleganter.
// Pseudocode, nicht ausprobiert:
switch (Type.GetTypeCode(typeof(T)))
{
case ArticleModel:
return dbContext.Articles.ToList() as IList
break;
case CategoryModel:
return dbContext.Categories.ToList() as IList
break;
default:
throw new Exception("Der PersistenceProvider kann mit dem übergebenen Typen nicht umgehen...");
}
Wie sieht die Lebenszeit des Datenbank-Kontexts aus? Sollte der PersistenceProvider einen Kontext übergeben bekommen oder ist es i.O. hier einen im Konstruktor zu erzeugen und im Destruktor freizugeben?
Das Gebiet und auch C# sind recht neu für mich. Ich hoffe die verbliebenen Fragen könnten geklärt werden.
Besten Dank und einen guten Rutsch!
Kenne ich,
das passiert ganz schnell.
Jetzt ist aber alles bestens.
Beste Grüße
HP
Ja, hat sich leider eingeschlichen. Wurde von mir rausgenommen und geändert. Sollte nun mit einer Basis-Installation funktionieren. Danke für den Hinweis.
Hallo Norbert,
kann es sein, dass man die Windows Phone Dev. Tools für VS installiert haben muss um dein Sample zu laden ?
Beste Grüße
HP